# load the library
library(tidyverse)
fn_Bachum <- "https://raw.githubusercontent.com/HydroSimul/Web/main/data_share/Bachum_2763190000100.csv"
fn_Datatype <- "https://raw.githubusercontent.com/HydroSimul/Web/main/data_share/load_Datatype.txt"Data Loading
This Aritcl will show the process to load data from other files. I t will divide into four paties: plain text (read able ASCII), Excel, NetCDF and spatial data.
Overview:

1 Plain text File
For more details about date (file) format, you can refer to the article titled Basic Data & File Format.
1.1 Example File
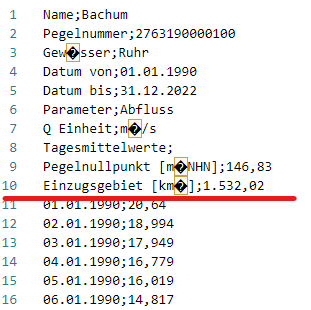
Let’s start with an example CSV file named Bachum_2763190000100.csv. This file contains pegel discharge data and is sourced from open data available at ELWAS-WEB NRW. You can also access it directly from the internet via Github, just like you would access a local file.
Take a look:
1.2 Library and functions
First, we need to load the necessary library tidyverse. This library collection includes readr for reading files and dplyr for data manipulation, among others.
And, we set the URL address as the file path (including the file name).
The documentation for the readr library is available online and can be accessed at https://readr.tidyverse.org.
Of particular interest are the following functions:
We can observe that the CSV file is divided by semicolons. Therefore, it’s more appropriate to use read_csv2() rather than read_csv().
The difference between read_*() functions in the readr package is determined by the delimiter character used in the files:

# load the library
import pandas as pd
fn_Bachum = "https://raw.githubusercontent.com/HydroSimul/Web/main/data_share/Bachum_2763190000100.csv"
fn_Datatype = "https://raw.githubusercontent.com/HydroSimul/Web/main/data_share/load_Datatype.txt"The documentation for the pandas library is available online and can be accessed at https://pandas.pydata.org/docs/index.html.
Of particular interest are the following functions:
1.3 Metadata Handel
Metadata can vary widely between datasets, so it’s handled separately from the data body.
There are three ways to deal with metadata:
Directly Ignore: This approach involves ignoring metadata when it’s redundant or readily available from other data sources, such as file names or external references.
Extract from Text: When metadata is crucial but not in table form, you can extract information from text strings. For more information, refer to the section on string manipulation Section 3.
Read as a Second Table: If metadata is well-organized in a tabular format, it can be read as a separate table to facilitate its use.
In the Bachum_2763190000100.csv file, you will find that there are 10 lines of metadata, which are well-organized in a tabular format. However, it’s important to note that the consistency in values column varies.
1.3.1 Directly Ignore use grguments skip
# skip = 10
read_csv2(fn_Bachum, skip = 10, n_max = 10, col_names = FALSE)# A tibble: 10 × 2
X1 X2
<chr> <dbl>
1 01.01.1990 20.6
2 02.01.1990 19.0
3 03.01.1990 17.9
4 04.01.1990 16.8
5 05.01.1990 16.0
6 06.01.1990 14.8
7 07.01.1990 14.3
8 08.01.1990 14.0
9 09.01.1990 14.4
10 10.01.1990 14.51.3.2 Read metadata as table
When directly reading all metadata into one table, you may encounter mixed data types. In the metadata, there are three data types:
- Numeric: Examples include
PegelnullpunktandEinzugsgebiet. - String: This category covers fields like
Name,Pegelnummer, and others. - Date: Date values are present in columns like
Datum vonandDatum bis.
In a data frame (tibble), columns must have the same data type. Consequently, R will automatically convert them to a single data type, which is typically string.
To address this situation, you should specify the data type you want to read. For example, to read the date values in lines 4 and 5, you can use the following settings: 1. skip = 3 to skip the first three lines of metadata. 2. n_max = 2 to read the next two lines (lines 4 and 5) as date values.
# skip = 3
read_csv2(fn_Bachum, skip = 3, n_max = 2, col_names = FALSE)# A tibble: 2 × 2
X1 X2
<chr> <chr>
1 Datum von 01.01.1990
2 Datum bis 31.12.2022df_bach = pd.read_csv(fn_Bachum, skiprows=3, nrows=2, header=None, delimiter=';', encoding='latin-1')
print(df_bach) 0 1
0 Datum von 01.01.1990
1 Datum bis 31.12.2022Unfortunately, R may not always recognize date values correctly, so you may need to perform additional steps for conversion:
After Reading: This involves transforming the data from its initial format to the desired date format within your R environment.
Set the Data Type by Reading: Another approach is to set the data type while reading the data.
More details in the next section:
1.4 Load tabular data
To read the first 10 lines of metadata, you can use the n_max setting with a value of n_max = 10 in the read_csv2() function.
read_csv2(fn_Bachum, n_max = 10, col_names = FALSE)# A tibble: 10 × 2
X1 X2
<chr> <chr>
1 "Name" "Bachum"
2 "Pegelnummer" "2763190000100"
3 "Gew\xe4sser" "Ruhr"
4 "Datum von" "01.01.1990"
5 "Datum bis" "31.12.2022"
6 "Parameter" "Abfluss"
7 "Q Einheit" "m\xb3/s"
8 "Tagesmittelwerte" <NA>
9 "Pegelnullpunkt [m\xfcNHN]" "146,83"
10 "Einzugsgebiet [km\xb2]" "1.532,02" After dealing with the metadata, we can proceed to load the data body using the readr::read_*() function cluster. Plain text files typically store data in a tabular or matrix format, both of which have at most two dimensions. When using the readr::read_() function, it automatically returns a tibble. If your data in the text file is in matrix format, you can use conversion functions like as.matrix() to transform it into other data structures.
# 1. load
tb_Read <- read_csv2(fn_Bachum, skip = 10, n_max = 10, col_names = FALSE)
tb_Read# A tibble: 10 × 2
X1 X2
<chr> <dbl>
1 01.01.1990 20.6
2 02.01.1990 19.0
3 03.01.1990 17.9
4 04.01.1990 16.8
5 05.01.1990 16.0
6 06.01.1990 14.8
7 07.01.1990 14.3
8 08.01.1990 14.0
9 09.01.1990 14.4
10 10.01.1990 14.5# 2. convert
df_Read <- as.data.frame(tb_Read)
mat_Read <- as.matrix(tb_Read)
df_Read X1 X2
1 01.01.1990 20.640
2 02.01.1990 18.994
3 03.01.1990 17.949
4 04.01.1990 16.779
5 05.01.1990 16.019
6 06.01.1990 14.817
7 07.01.1990 14.296
8 08.01.1990 13.952
9 09.01.1990 14.403
10 10.01.1990 14.500mat_Read X1 X2
[1,] "01.01.1990" "20.640"
[2,] "02.01.1990" "18.994"
[3,] "03.01.1990" "17.949"
[4,] "04.01.1990" "16.779"
[5,] "05.01.1990" "16.019"
[6,] "06.01.1990" "14.817"
[7,] "07.01.1990" "14.296"
[8,] "08.01.1990" "13.952"
[9,] "09.01.1990" "14.403"
[10,] "10.01.1990" "14.500"tb_Read = pd.read_csv(fn_Bachum, skiprows=10, nrows=10, header=None, delimiter=';', decimal=',', encoding='latin-1')
print(tb_Read) 0 1
0 01.01.1990 20.640
1 02.01.1990 18.994
2 03.01.1990 17.949
3 04.01.1990 16.779
4 05.01.1990 16.019
5 06.01.1990 14.817
6 07.01.1990 14.296
7 08.01.1990 13.952
8 09.01.1990 14.403
9 10.01.1990 14.5001.5 Data type
In this section, we will work with a custom-made text file that contains various data types and formats. The file consists of three rows, with one of them serving as the header containing column names, and six columns in total.
Let’s take a look:

Actually the function will always guse the dattype for each column, when the data really normally format the function will return the right datatype for the data:
read_table(fn_Datatype)# A tibble: 2 × 6
int float_en float_de date_en date_de str
<dbl> <dbl> <chr> <date> <chr> <chr>
1 1 0.1 0,1 2023-09-15 15.09.2023 en
2 9 9.6 9,6 2023-09-16 16.09.2023 de df = pd.read_table(fn_Datatype)
print(df) int float_en float_de date_en date_de str
0 1 0.1 0,1 2023-09-15 15.09.2023 en
1 9 9.6 9,6 2023-09-16 16.09.2023 deprint(df.dtypes)int int64
float_en float64
float_de object
date_en object
date_de object
str object
dtype: objectBy default, functions like readr::read_table() in R and pandas.read_table() in Python will attempt to guess data types automatically when reading data. Here’s how this guessing typically works:
If a column contains only numbers and decimal dots (periods), it will be recognized as numeric (double in R and int or float in Python).
If a date is formatted in “Y-M-D” (e.g., “2023-08-27”) or “h:m:s” (e.g., “15:30:00”) formats, it may be recognized as a date or time type. Nur in R
If the data type cannot be confidently determined, it is often treated as a string (str in R and object in Python).
This automatic guessing is convenient, but it’s essential to verify the inferred data types, especially when working with diverse datasets.
1.5.1 Set the Data Type by Reading
Explicitly setting data types using the col_types (in R) or dtype (in Python) argument can help ensure correct data handling.
To address the issue of date recognition, you can set the col_types argument, you can use a compact string representation where each character represents one column:
c: Characteri: Integern: Numberd: Doublel: Logicalf: FactorD: DateT: Date Timet: Time?: Guess_or-: Skip
to "cD" when reading the data. This informs the function that the first column contains characters (c) and the second column contains Dates (D).
read_table(fn_Datatype, col_types = "iddDDc")# A tibble: 2 × 6
int float_en float_de date_en date_de str
<int> <dbl> <dbl> <date> <date> <chr>
1 1 0.1 NA 2023-09-15 NA en
2 9 9.6 NA 2023-09-16 NA de read_table(fn_Datatype, col_types = "idd?Dc")# A tibble: 2 × 6
int float_en float_de date_en date_de str
<int> <dbl> <dbl> <date> <date> <chr>
1 1 0.1 NA 2023-09-15 NA en
2 9 9.6 NA 2023-09-16 NA de To set data types when reading data using functions pandas.read_*, you have three main choices by using the dtype parameter:
str: Specify the data type as a string.int: Specify the data type as an integer.float: Specify the data type as a floating-point number.
However, you can also use the dtype parameter with a callable function to perform more advanced type conversions. Some commonly used functions include:
pd.to_datetime: Converts a column to datetime format.pd.to_numeric: Converts a column to numeric (integer or float) format.pd.to_timedelta: Converts a column to timedelta format.
# Define column names and types as a dictionary
col_types = {"X1": str, "X2": pd.to_datetime}
# Read the CSV file, skip 3 rows, read 2 rows, and specify column names and types
df = pd.read_csv(fn_Bachum, skiprows=3, nrows=2, header=None, delimiter=';', names=["X1", "X2"], dtype=col_types, encoding='latin-1')
# Display the loaded data
print(df)DON’T RUN Error, because data doesn’t match the default format of ‘Y-m-d’.
Unfortunately, the default date format in R and Python may not work for German-style dates like “d.m.Y” as R and Python primarily recognizes the “Y-m-d” format.
1.5.2 After Reading
To address this issue, you can perform date conversions after reading the data:
Using function as.Date() and specify the date format using the format argument, such as format = "%d.%m.%Y".
df_Date <- read_csv2(fn_Bachum, skip = 3, n_max = 2, col_names = FALSE)
df_Date$X2 <- df_Date$X2 |> as.Date(format = "%d.%m.%Y")
df_Date# A tibble: 2 × 2
X1 X2
<chr> <date>
1 Datum von 1990-01-01
2 Datum bis 2022-12-31df_Date = pd.read_csv(fn_Bachum, skiprows=3, nrows=2, header=None, delimiter=';', encoding='latin-1')
# Display the loaded data
print(df_Date) 0 1
0 Datum von 01.01.1990
1 Datum bis 31.12.2022# 2. Convert the second column (X2) to a date format
df_Date[1] = pd.to_datetime(df_Date[1], format='%d.%m.%Y')
# Display the DataFrame with the second column converted to date format
print(df_Date) 0 1
0 Datum von 1990-01-01
1 Datum bis 2022-12-31print(df_Date.dtypes)0 object
1 datetime64[ns]
dtype: object2 Excel File
When we discuss the combination of the software Excel with data files in formats such as .xls or .xlsx, there are numerous possibilities for data science. However, when we specifically consider the file format, there are distinct differences between plain text and Excel files:
Plain Text File vs. Excel for Data Storage
| Aspect | Plain Text File | Excel File |
|---|---|---|
| Data Structure | Typically stores data in a tabular format or matrix. | Stores data in structured worksheets with multiple tables (sheets). |
| Compatibility | Universally compatible with various software and programming languages. | Compatibility may vary, and not all software can read Excel files. |
| Human-Readable | Easily readable by humans in a simple text format. | Readable by humans but may include formatting that isn’t immediately apparent. |
| Data Transfer | Easily shared and transferred between different platforms and systems. | May require conversion or specific software for seamless data transfer. |
| Data Import/Export | May require custom import/export scripts for specific applications. | Supports standardized import/export formats for various applications. |
| Version Control | Suitable for version control systems (e.g., Git) for tracking changes. | Not well-suited for version control due to binary format and complex changes. |
| Data Analysis | Requires additional software to analyze data (e.g., R or Python). | Offers built-in data analysis tools (e.g., formulas, charts). |
| Openness and Access | Open and transparent; data can be accessed and edited with any text editor. | Proprietary format may require specific software (Microsoft Excel) to access and edit. |
Unlike plain text files, Excel files have the capability to contain multiple tables, known as sheets. In Excel, each cell within a sheet is uniquely identified by its specific coordinates. Rows are indexed with numerical values, and columns are identified using alphabetical indices. By combining the sheet name with these coordinates, it is possible to precisely locate any cell within an Excel file and retrieve the value it contains.
2.1 Example File
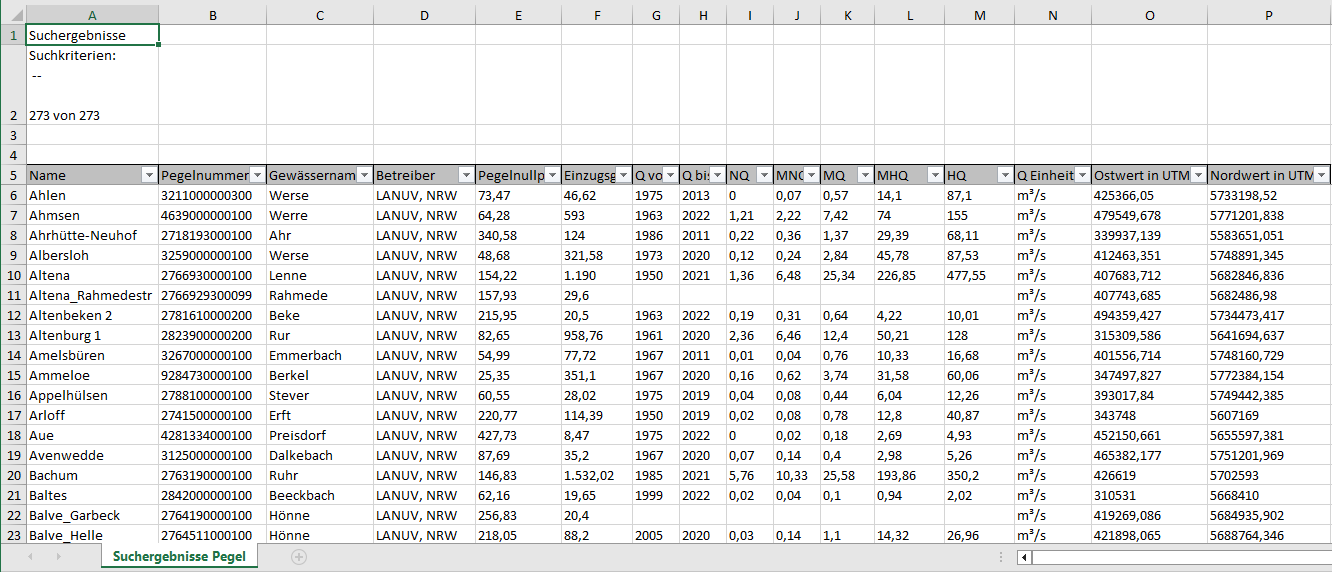
Let’s begin with an example Excel file named Pegeln_NRW.xlsx. This file contains information about measurement stations in NRW (Nordrhein-Westfalen, Germany) and is sourced from open data available at ELWAS-WEB NRW. You can also access it directly from Github.
Take a look:
2.2 Library and functions
To load the necessary library, readxl, and access its help documentation, you can visit this link. The readxl::read_excel() function is versatile, as it can read both .xls and .xlsx files and automatically detects the format based on the file extension. Additionally, you have the options of using read_xls() for .xls files and read_xlsx() for .xlsx files. More details in the Page.
# load the library
library(readxl)
# The Excel file cannot be read directly from GitHub. You will need to download it to your local machine first
fn_Pegeln <- "C:\\Lei\\HS_Web\\data_share/Pegeln_NRW.xlsx"The pandas.read_excel() function is versatile, as it can read both .xls and .xlsx files and automatically detects the format based on the file extension. More details in the Page.
import pandas as pd
# Specify the path to the Excel file
fn_Pegeln = "C:\\Lei\\HS_Web\\data_share/Pegeln_NRW.xlsx"2.3 Load tabular data
Similar to plain text files, metadata is often provided before the data body in Excel files. In Excel, each cell can be assigned a specific data type, while in R tables (data.frame or tibble), every column must have the same data type. This necessitates separate handling of metadata and data body to ensure that the correct data types are maintained.
Unlike plain text files where we can only select lines to load, Excel allows us to define coordinates to access a specific celles-box wherever they are located.
2.3.1 First try without any setting
# try without setting
tb_Pegeln <- read_excel(fn_Pegeln)
tb_Pegeln# A tibble: 277 × 16
Suchergebnisse Pegel.…¹ ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 "Suchkriterien:\n -- \… <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
2 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
3 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
4 "Name" Pege… Gewä… Betr… Pege… Einz… Q von Q bis NQ MNQ
5 "Ahlen" 3211… Werse LANU… 73,47 46,62 1975 2013 0 0,07
6 "Ahmsen" 4639… Werre LANU… 64,28 593 1963 2022 1,21 2,22
7 "Ahrhütte-Neuhof" 2718… Ahr LANU… 340,… 124 1986 2011 0,22 0,36
8 "Albersloh" 3259… Werse LANU… 48,68 321,… 1973 2020 0,12 0,24
9 "Altena" 2766… Lenne LANU… 154,… 1.190 1950 2021 1,36 6,48
10 "Altena_Rahmedestraße" 2766… Rahm… LANU… 157,… 29,6 <NA> <NA> <NA> <NA>
# ℹ 267 more rows
# ℹ abbreviated name: ¹`Suchergebnisse Pegel.xlsx 14.09.2023 10:01`
# ℹ 6 more variables: ...11 <chr>, ...12 <chr>, ...13 <chr>, ...14 <chr>,
# ...15 <chr>, ...16 <chr># Read the Excel file into a pandas DataFrame
tb_Pegeln = pd.read_excel(fn_Pegeln)
# Display the DataFrame
print(tb_Pegeln) Suchergebnisse Pegel.xlsx 14.09.2023 10:01 ... Unnamed: 15
0 Suchkriterien:\n -- \n\n273 von 273 Datensätze... ... NaN
1 NaN ... NaN
2 NaN ... NaN
3 Name ... Nordwert in UTM
4 Ahlen ... 5733198,52
.. ... ... ...
272 Wolbeck ... 5750912,504
273 Wt-Kluserbrücke ... 5679856
274 Zeppenfeld ... 5626270,319
275 Zerkall 1 ... 5618750,896
276 Zerkall 2 ... 5617784,98
[277 rows x 16 columns]When we provide only the file name to the function, we will always retrieve all the content from the first sheet. However, due to the limitations in R (and Python) tables, every column will be recognized as the same data type, typically character.
2.3.2 Give a range
# using the range argument
tb_Pegeln_Range <- read_excel(fn_Pegeln, range = "Suchergebnisse Pegel!A5:P10")
tb_Pegeln_Range# A tibble: 5 × 16
Name Pegelnummer Gewässername Betreiber `Pegelnullpunkt [müNHN]`
<chr> <chr> <chr> <chr> <chr>
1 Ahlen 3211000000300 Werse LANUV, NRW 73,47
2 Ahmsen 4639000000100 Werre LANUV, NRW 64,28
3 Ahrhütte-Neuhof 2718193000100 Ahr LANUV, NRW 340,58
4 Albersloh 3259000000100 Werse LANUV, NRW 48,68
5 Altena 2766930000100 Lenne LANUV, NRW 154,22
# ℹ 11 more variables: `Einzugsgebiet [km²]` <chr>, `Q von` <chr>,
# `Q bis` <chr>, NQ <chr>, MNQ <chr>, MQ <chr>, MHQ <chr>, HQ <chr>,
# `Q Einheit` <chr>, `Ostwert in UTM` <chr>, `Nordwert in UTM` <chr>
Warning
The data type of “Pegelnullpunkt [müNHN]” appears to be incorrect due to improper settings in Excel.
Compared to R, Python doesn’t have a direct equivalent to the “Range”. Instead, you can achieve a similar method like plain text with skiprows. Additionally, you can use usecols to specify the columns you want to include.
# Read the specified range from the Excel file into a pandas DataFrame
tb_Pegeln_Range = pd.read_excel(fn_Pegeln, sheet_name="Suchergebnisse Pegel", skiprows = 4, usecols="A:P")
# Display the DataFrame
print(tb_Pegeln_Range) Name Pegelnummer ... Ostwert in UTM Nordwert in UTM
0 Ahlen 3211000000300 ... 425366,05 5733198,52
1 Ahmsen 4639000000100 ... 479549,678 5771201,838
2 Ahrhütte-Neuhof 2718193000100 ... 339937,139 5583651,051
3 Albersloh 3259000000100 ... 412463,351 5748891,345
4 Altena 2766930000100 ... 407683,712 5682846,836
.. ... ... ... ... ...
268 Wolbeck 3289100000100 ... 416214,865 5750912,504
269 Wt-Kluserbrücke 2736510000100 ... 371494 5679856
270 Zeppenfeld 2722590000100 ... 430354,152 5626270,319
271 Zerkall 1 2823500000100 ... 320063,421 5618750,896
272 Zerkall 2 2823490000100 ... 319449,788 5617784,98
[273 rows x 16 columns]2.4 Data type
Compared to plain text files, Excel data already contains data type information for each cell. Therefore, the data type will be directly determined by the data type specified in Excel.
However, there are instances where the data type in Excel is not correctly set, so manual data type conversion may be necessary. For more details, refer to Section 1.5.
3 Text & String
Coming soon …